Table of contents

ImageNet Large Scale Visual Recognition Challenge (ILSVRC) is an annual computer vision competition held to assess the performance of algorithms on large-scale image classification and object detection tasks. The competition began in 2010, and has been a driving force behind the rapid progress in computer vision research in recent years.
The challenge is hosted by the ImageNet project, which is a large-scale image database created by researchers at Princeton University. ImageNet contains over 14 million images of more than 20,000 object categories. The dataset has been used to train and evaluate various machine learning models, including deep neural networks.
The ILSVRC competition consists of two tracks: classification and detection. The classification track requires algorithms to assign one of 1,000 possible labels to each image. The detection track requires algorithms to identify and locate all instances of objects of 200 categories in an image.
The competition has been a major driving force in the development of deep learning algorithms for image classification and object detection. In particular, the winning entries in recent years have all been based on deep convolutional neural networks, which have achieved unprecedented levels of accuracy.
The ILSVRC competition has also been a major driver of progress in the field of transfer learning. Transfer learning is the process of using a pre-trained deep learning model as a starting point for a new task, rather than training a model from scratch. The pre-trained model is first trained on a large dataset such as ImageNet, and then fine-tuned on the smaller dataset for the new task. This approach has been shown to achieve state-of-the-art results on a wide range of computer vision tasks.
The Motivation
The motivation for the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) was to advance the state of the art in computer vision and to enable researchers to develop better algorithms for object recognition. Prior to the ILSVRC, many object recognition algorithms were based on hand-engineered features, which were time-consuming to design and not as accurate as needed. The goal of the ILSVRC was to encourage researchers to develop algorithms that could learn useful features from large amounts of data, and to push the limits of what was possible in computer vision.
Another motivation for the challenge was the need to evaluate the performance of different algorithms on a standardized dataset. With so many different algorithms and approaches being developed in the field of computer vision, it was difficult to compare their performance without a common benchmark. The ILSVRC provided such a benchmark, allowing researchers to objectively evaluate the effectiveness of their algorithms and compare them with others.
The ILSVRC also helped to raise the profile of computer vision and the potential applications of this technology. With the development of deep learning and the success of the ILSVRC, computer vision has become an increasingly important field in artificial intelligence, with applications in areas such as self-driving cars, robotics, and medical imaging.
Challenge Story (2013 – 2017)
The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) was held annually from 2010 to 2017:
1- ILSVRC2010: The first ImageNet challenge took place in 2010 and featured 1,000 object categories with roughly 1,500 images per category. The aim was to develop algorithms capable of classifying objects within these categories.
2- ILSVRC2011: The second challenge was held in 2011 and saw a significant increase in the number of categories, from 1,000 to 21,000. Each category contained around 100-500 images, and the goal was to classify images into these categories.
3- ILSVRC2012: The 2012 challenge featured 1.2 million images across 1,000 object categories, making it the largest publicly available image recognition dataset at the time. The challenge also introduced a new task of object detection, where algorithms had to not only identify the object in the image, but also locate it within the image.
4- ILSVRC2013: The fourth challenge, held in 2013, featured the same number of categories and images as the 2012 challenge. However, it also introduced a new detection task for localizing objects with bounding boxes.
5- ILSVRC2014: The 2014 challenge increased the number of categories to 1,000 and the number of images to 1.2 million. The challenge also introduced a new task of object detection in video, where algorithms had to identify and localize objects in a sequence of frames.
6- ILSVRC2015: The fifth challenge featured the same categories and images as the 2014 challenge, but introduced a new task of fine-grained recognition. In this task, the goal was to classify objects into subcategories within each of the 200 bird and 200 aircraft categories.
7- ILSVRC2016: The 2016 challenge was similar to the 2015 challenge, but with an increased emphasis on object detection and localization in both images and videos. The challenge also introduced a new task of scene recognition, where algorithms had to identify the type of scene depicted in an image.
8- ILSVRC2017: The 2017 challenge had the same categories and images as the 2016 challenge, but with an emphasis on incremental learning. The goal was to develop algorithms that could continually learn and improve their performance over time.
Since 2018, the challenge has been replaced by the COCO (Common Objects in Context) and Open Images challenges.
Results (2013 – 2017)
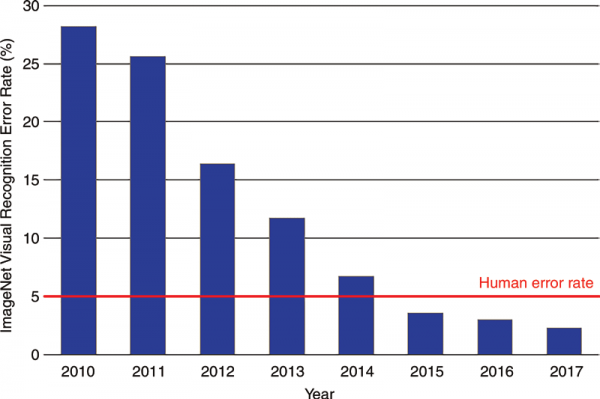
Here's a summary of the results of the ImageNet Large Scale Visual Recognition Challenge for each year:
1- ILSVRC2010: The first year of the challenge was held in 2010, and it focused on the problem of image classification. The winning entry, submitted by a team from the University of Toronto, achieved an accuracy rate of 28.2%, which was significantly higher than the previous best result of 18.1%. The winning algorithm was a combination of a support vector machine (SVM) and a deep neural network.
2- ILSVRC2011: The second year of the challenge continued to focus on image classification. The winning entry, submitted by a team from the University of Toronto, achieved an accuracy rate of 47.1%. This was a significant improvement over the previous year's winner, and it was achieved using a deep neural network with multiple layers.
3- ILSVRC2012: In 2012, the challenge expanded to include object detection and image localization in addition to image classification. The winning entry, submitted by a team from the University of Toronto, achieved an accuracy rate of 15.3% for classification, 53.3% for localization, and 29.4% for detection. The winning algorithm was based on a deep convolutional neural network (CNN) with multiple layers.
4- ILSVRC2013: The 2013 challenge focused on detecting and classifying objects in images. The winning entry, submitted by a team from Microsoft Research, achieved an accuracy rate of 63.7%. The winning algorithm used a deep CNN with multiple layers and a technique known as "spatial pyramid pooling" to achieve better results.
5- ILSVRC2014: The 2014 challenge continued to focus on object detection and classification. The winning entry, submitted by a team from Google, achieved an accuracy rate of 74.8%. The winning algorithm was based on a deep CNN with multiple layers and a novel approach to image augmentation that helped to improve accuracy.
6- ILSVRC2015: The 2015 challenge focused on object detection and localization. The winning entry, submitted by a team from Microsoft Research, achieved an accuracy rate of 33.7% for detection and 48.1% for localization. The winning algorithm used a deep CNN with multiple layers and a technique known as "Faster R-CNN" to achieve better results.
7- ILSVRC2016: The 2016 challenge focused on detecting and classifying objects in images. The winning entry, submitted by a team from Megvii Inc., achieved an accuracy rate of 96.4%. The winning algorithm used a deep CNN with multiple layers and a novel approach to image augmentation that helped to improve accuracy.
8- ILSVRC2017: In 2017, the challenge focused on detecting and classifying objects in videos. The winning entry, submitted by a team from Tencent Youtu Lab, achieved an accuracy rate of 80.7%. The winning algorithm used a deep CNN with multiple layers and a technique known as "Two-Stream Inflated 3D Convolutional Networks" to achieve better results.
Conclusion
Overall, the ImageNet Large Scale Visual Recognition Challenge has had a significant impact on the field of computer vision and machine learning. It has led to the development of new algorithms, new techniques, and new applications, and has helped to advance our understanding of how machines can recognize and understand visual information.